How I Built a Free Geolocation API With Cloudflare Workers and D1
A practical build story for a free REST API with countries, states, cities, IP geolocation, Cloudflare Workers, D1, Hono, and SQLite FTS5.
Every app eventually needs boring location data.
Country dropdowns. State selectors. City autocomplete. Timezone hints. IP-based defaults. The work is not hard, but the options are usually annoying: pay for an API, sign up for a free key with tiny limits, or self-host a database dump for a form field.
I wanted the boring version: no key, no signup, no server to babysit.
Key Takeaways
- The API serves 252 countries, 5,024 states, 232,008 cities, 312 timezones, and 178 currencies
- Cloudflare’s
request.cfgives caller location hints; D1 enriches them with full records- SQLite FTS5 handles global search without Algolia or Elasticsearch
- The best product decision was deleting auth, API keys, and app-level rate limits
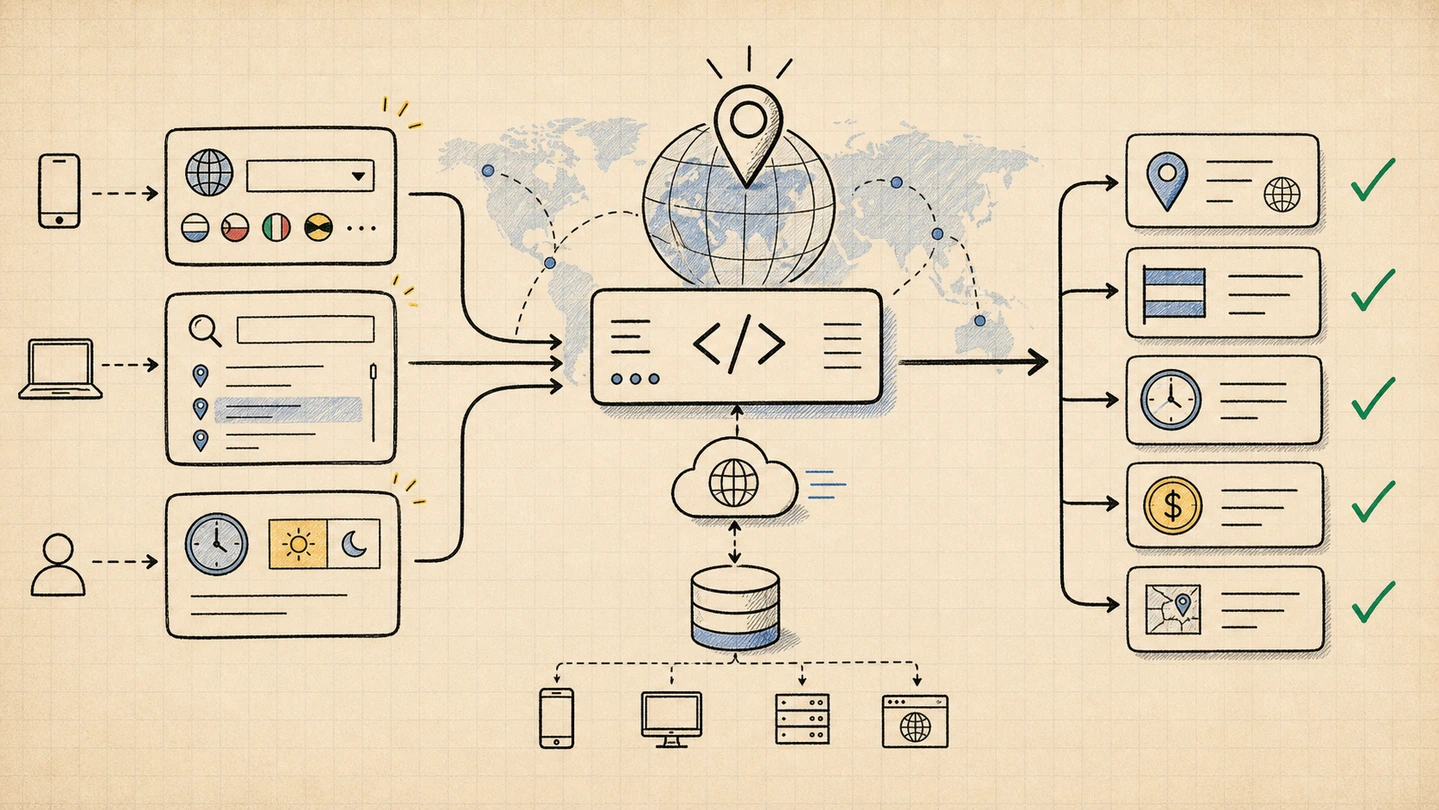
Why existing geo APIs are annoying
Most geo APIs make static data feel dynamic.
Country names, ISO codes, currencies, timezones, and state boundaries come from public datasets. Charging per request for a list of countries is a business model, not a technical requirement.
Free APIs exist, but many still require registration before a developer can run one curl. Some have tiny daily limits. Some are slow because every request goes back to the same origin.
Self-hosting fixes control but adds chores: download dumps, import them, expose routes, write search, keep everything updated. For a country dropdown, that is a lot of infrastructure.
The shape I wanted was simpler:
| Requirement | Why it mattered |
|---|---|
| No API key | Let people try it before they care |
| Cached static data | Countries and timezones do not change per request |
| Real database queries | JSON blobs are fine until search and pagination show up |
| Self-hostable | A fork should not depend on my domains |
| Open data sources | No mystery dataset hiding behind the API |
That led to Cloudflare Workers, D1, and a small Hono router.
The architecture is intentionally small
The public API is one Worker with one runtime dependency: Hono for routing and CORS.
There is no ORM, no API gateway, no auth service, and no external search cluster. The Worker talks to D1 through a binding, serves static assets through Workers Static Assets, and exposes the OpenAPI spec from the same deployment.
| Host | What the Worker returns |
|---|---|
geocoded.me | Landing page, dashboard, explorer, docs |
api.geocoded.me | JSON API |
/openapi.json | OpenAPI 3.1 document |
/postman.json | Postman collection |
The important bit is not cleverness. It is drift control.
The docs site and API ship together, so the documentation cannot lag behind a separate backend deployment.
What actually shipped?
The API is mostly boring REST.
The useful parts are the defaults: all list endpoints are paginated, every endpoint supports field selection, and static responses get long-lived cache headers.
The first useful route is also the shortest:
curl https://api.geocoded.meThat returns the caller’s Cloudflare location hints, then enriches them with full country, state, and city records when D1 can match them.
Cloudflare already has the first location signal
Cloudflare adds a cf object to inbound Worker requests. When available, it includes useful hints like country, region, city, coordinates, timezone, ASN, and colo.
That is enough to answer “where is this request probably coming from?” It is not enough to power a product UI.
Cloudflare might give you country: "US" and regionCode: "CA". Geocoded turns that into full records: country name, flag emoji, currency, phone code, state name, timezone, and city metadata.
| Response type | Cache policy | Reason |
|---|---|---|
| Countries, states, cities, timezones, currencies | public, max-age=31536000, immutable | Data changes through the pipeline, not per request |
| Caller location | private, no-store | Your IP location changes with VPNs, travel, and networks |
| OpenAPI/Postman docs | Short public cache | Useful to cache, but easier to refresh |
The city match is deliberately conservative: country + state + city name. It works well enough for a free API, but I would not pretend it is a parcel-grade geocoder.
Why D1 was enough
D1 gave me the part JSON files do not: queries.
Countries, states, cities, timezones, and currencies live in normal tables with indexes. Global search uses SQLite FTS5, so ?q=san can search across countries, states, and cities without an external search service.
The whole schema is still small. The checked-in JSON output is under 70 MB, and the D1 database stays well below the current D1 storage limits.
| Feature | Why D1 fit |
|---|---|
| Pagination | LIMIT, OFFSET, and a simple opaque cursor |
| Lookup routes | Indexed country/state/city columns |
| Full-text search | FTS5 virtual table |
| Self-hosting | wrangler d1 create, migrations, seed script |
| No database server | D1 is managed and bound directly to the Worker |
If this becomes a fuzzy geocoder, I would revisit the storage/search layer. For country/state/city lookup, D1 is enough.
Field selection is the cheap GraphQL
A full country record has a lot of fields: translations, neighbours, languages, driving side, literacy rate, timezone list, currency info, postal code metadata, and more.
Most callers do not need all of that.
So every endpoint accepts ?fields=:
| Request | Payload intent |
|---|---|
/countries?fields=name,iso2,emoji | Build a country selector |
/countries/US?fields=name,capital,currency | Show a compact country profile |
/?fields=ip,country,countryInfo.name,countryInfo.emoji | Enrich caller location without the full country object |
I considered GraphQL for about five minutes.
Then I remembered what I actually wanted: comma-separated fields, dot notation for nested objects, and no new runtime dependency.
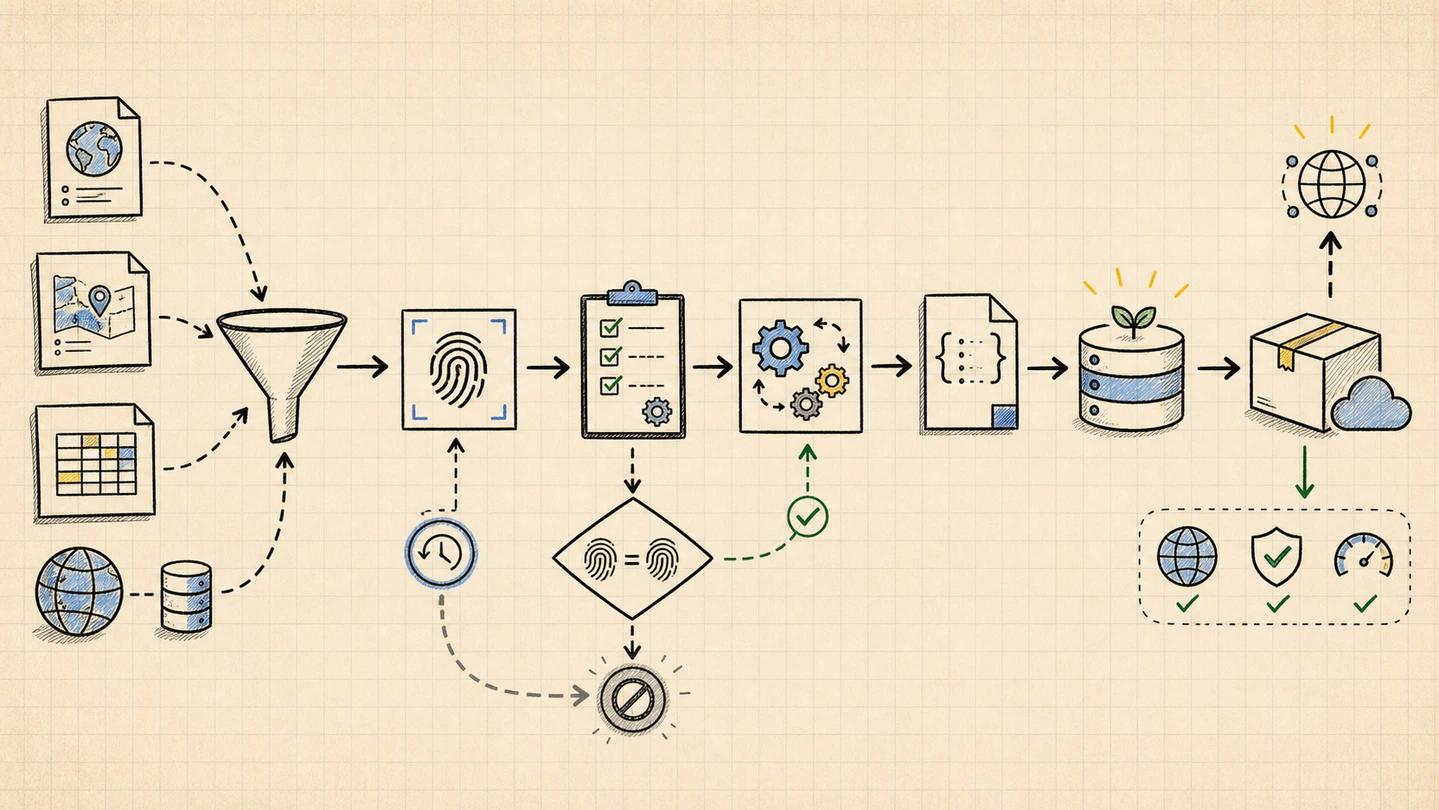
The data pipeline is the real product
The API is small because the pipeline does the messy work before deploy time.
The data comes from institutional sources: GeoNames, Unicode CLDR, IANA, ISO 4217, Natural Earth, Wikidata, trusted boundary sources, and vendored CIA World Factbook demonyms.
| Source | Used for |
|---|---|
| GeoNames | Countries, admin divisions, cities, coordinates, population, timezones |
| CLDR | Translations, currency symbols, GDP/literacy hints, week/time/measurement data |
| IANA | Timezone IDs and country mappings |
| ISO 4217 | Currency codes, names, decimal digits |
| Natural Earth | ISO 3166-2 subdivision codes and types |
| Wikidata | Missing subdivision IDs and capitals |
| CIA World Factbook | Nationalities/demonyms |
The pipeline fetches source files daily, hashes them with SHA-256, and exits without writing anything when upstream data has not changed.
When something changes, it builds five JSON files, validates them, pushes the public output into the API repo, and the API repo’s seed workflow loads D1.
That gives the Worker a boring job: read tables and return JSON.
The best feature was removing features
The first version had API key registration.
Email form. Confirmation flow. Key storage. Per-key limits.
Then I looked at it and asked: what am I protecting?
The source data is public. The output is public. The project goal is adoption. Putting registration in front of a free country list only makes the product worse.
| Removed | What got better |
|---|---|
| API keys | One curl proves the API works |
| Account creation | No database table for users |
| Per-key limits | No identity layer just to throttle public data |
| Email confirmation | No delivery, spam, or bounce handling |
There are still platform limits and abuse protection at Cloudflare’s layer. I just stopped building application-level gates for a dataset that was meant to be open.
Where this breaks down
City matching is name-based. The location endpoint matches Cloudflare’s city hint against D1 cities inside the detected country and state. Cities with identical names in the same state can collide.
D1 has storage limits. The current dataset fits comfortably. A future “every hamlet on earth” version would need a different storage/search plan.
The data is as good as its sources. Cross-referencing helps, but upstream mistakes still make it through sometimes.
The stack is Cloudflare-specific. Self-hosters need Workers, D1, Wrangler, and the request.cf object for the location endpoint.
That is a deliberate trade-off. This project optimizes for a tiny operational footprint, not cloud portability.
Try it
Start with the location endpoint:
curl https://api.geocoded.meThen grab slim country data:
curl "https://api.geocoded.me/countries?fields=name,iso2,emoji"Search and drill down:
curl "https://api.geocoded.me/search?q=san+francisco&type=city"
curl "https://api.geocoded.me/countries/IN/states?fields=name,iso2"
curl "https://api.geocoded.me/countries/US/states/CA/cities?limit=10"Timezones and currencies are separate resources:
curl "https://api.geocoded.me/timezones?fields=timezone,countryCodes&limit=5"
curl "https://api.geocoded.me/currencies?fields=code,name,symbol&limit=5"No API key. No signup. No demo account.
Free geolocation REST API on Cloudflare Workers -- countries, states, cities, IP lookup
What do you usually do for location data: pay for an API, ship a JSON package, self-host a dump, or hardcode the list and move on?